layout: true <div class="my-footer"><span>bit.ly/silge-rstudioconf-2</span></div> --- class: inverse, center, bottom background-image: url(figs/robert-bye-R-WtV-QyVnY-unsplash.jpg) background-size: cover # WELCOME! ### Text Mining Using Tidy Data Principles --- class: inverse, center, middle background-image: url(figs/p_and_p_cover.png) background-size: cover # Text Modeling <img src="figs/blue_jane.png" width="150px"/> ### USING TIDY PRINCIPLES .large[Julia Silge | rstudio::conf | 28 Jan 2020] --- class: middle, center .pull-left[ # <i class="fa fa-wifi"></i> Wifi network name .large[rstudio20] ] .pull-left[ # <i class="fa fa-key"></i> Wifi password .large[tidyverse20] ] --- <img src="figs/blue_jane.png" style="position:absolute;top:30px;right:30px;" width="100px"/> ## **Workshop policies** -- - .large[Identify the exits closest to you in case of emergency] -- - .large[Please review the rstudio::conf code of conduct that applies to all workshops] -- - .large[CoC issues can be addressed three ways:] - In person: contact any rstudio::conf staff member or the conference registration desk - By email: send a message to `conf@rstudio.com` - By phone: call 844-448-1212 -- - .large[Please do not photograph people wearing red lanyards] -- - .large[A chill-out room is available for neurologically diverse attendees on the 4th floor of tower 1] --- class: right, middle <img src="figs/blue_jane.png" width="150px"/> # Find me at... <a href="http://twitter.com/juliasilge"><i class="fa fa-twitter fa-fw"></i> @juliasilge</a><br> <a href="http://github.com/juliasilge"><i class="fa fa-github fa-fw"></i> @juliasilge</a><br> <a href="https://juliasilge.com"><i class="fa fa-link fa-fw"></i> juliasilge.com</a><br> <a href="https://tidytextmining.com"><i class="fa fa-book fa-fw"></i> tidytextmining.com</a><br> <a href="mailto:julia.silge@gmail.com"><i class="fa fa-paper-plane fa-fw"></i> julia.silge@gmail.com</a> --- class: left, top <img src="figs/blue_jane.png" width="150px"/> # Meet your TAs ## 💫 Emil Hvitfelt (coordinator) ## 💥 Jeroen Claes ## ✨ Kasia Kulma --- class: left, top <img src="figs/blue_jane.png" width="150px"/> # Asking for help -- ## 🆘 "I'm stuck" -- ## ⚠️ "I'm not stuck, but I need help on my computer" -- ## 🙋 "I need help understanding something" --- class: right, inverse, middle background-image: url(figs/p_and_p_cover.png) background-size: cover # TIDYING AND CASTING <h1 class="fa fa-check-circle fa-fw"></h1> --- background-image: url(figs/tmwr_0601.png) background-size: 900px --- class: inverse background-image: url(figs/p_and_p_cover.png) background-size: cover # Two powerful NLP techniques -- ### 💡 Topic modeling -- ### 💡 Text classification --- ## Let's install some packages ```r install.packages(c("tidyverse", "tidytext", "gutenbergr", "tidymodels", "stm", "glmnet")) ``` --- class: inverse background-image: url(figs/p_and_p_cover.png) background-size: cover # Topic modeling ### 📖 Each DOCUMENT = mixture of topics -- ### 📑 Each TOPIC = mixture of tokens --- class: top background-image: url(figs/top_tags-1.png) background-size: 800px --- class: center, middle, inverse background-image: url(figs/p_and_p_cover.png) background-size: cover # GREAT LIBRARY HEIST 🕵 --- ## **Downloading your text data** ```r library(tidyverse) library(gutenbergr) books <- gutenberg_download(c(164, 36, 1342, 1400), meta_fields = "title") books %>% count(title) ``` ``` ## # A tibble: 4 x 2 ## title n ## <chr> <int> ## 1 Great Expectations 20024 ## 2 Pride and Prejudice 13030 ## 3 The War of the Worlds 6474 ## 4 Twenty Thousand Leagues under the Sea 12135 ``` --- ## **Someone has torn your books apart!** 😭 .large[What do you predict will happen if we run the following code? 🤔] ```r by_chapter <- books %>% group_by(title) %>% mutate(chapter = cumsum(str_detect(text, regex("^chapter ", ignore_case = TRUE)))) %>% ungroup() %>% filter(chapter > 0) %>% unite(document, title, chapter) glimpse(by_chapter) ``` --- ## **Someone has torn your books apart!** 😭 .large[What do you predict will happen if we run the following code? 🤔] ```r by_chapter <- books %>% group_by(title) %>% mutate(chapter = cumsum(str_detect(text, regex("^chapter ", ignore_case = TRUE)))) %>% ungroup() %>% filter(chapter > 0) %>% unite(document, title, chapter) glimpse(by_chapter) ``` ``` ## Observations: 51,602 ## Variables: 3 ## $ gutenberg_id <int> 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, … ## $ text <chr> "CHAPTER ONE", "", "THE EVE OF THE WAR", "", "", "No one… ## $ document <chr> "The War of the Worlds_1", "The War of the Worlds_1", "T… ``` --- ## **Can we put them back together?** ```r library(tidytext) word_counts <- by_chapter %>% * unnest_tokens(word, text) %>% anti_join(get_stopwords()) %>% count(document, word, sort = TRUE) glimpse(word_counts) ``` ``` ## Observations: 131,104 ## Variables: 3 ## $ document <chr> "Great Expectations_57", "Great Expectations_7", "Pride and … ## $ word <chr> "joe", "joe", "mr", "biddy", "joe", "estella", "joe", "said"… ## $ n <int> 88, 70, 66, 63, 58, 58, 56, 53, 53, 50, 50, 50, 50, 47, 46, … ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[The dataset `word_counts` contains] - .large[the counts of words per book] - .large[the counts of words per chapter] - .large[the counts of words per line] --- ## **Can we put them back together?** ```r words_sparse <- word_counts %>% * cast_sparse(document, word, n) class(words_sparse) ``` ``` ## [1] "dgCMatrix" ## attr(,"package") ## [1] "Matrix" ``` ```r dim(words_sparse) ``` ``` ## [1] 193 18703 ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Is `words_sparse` a tidy dataset?] - .large[Yes ✅] - .large[No 🚫] --- ## **Train a topic model** Use a sparse matrix or a `quanteda::dfm` object as input ```r library(stm) topic_model <- stm(words_sparse, K = 4, verbose = FALSE, init.type = "Spectral") ``` --- ## **Train a topic model** Use a sparse matrix or a `quanteda::dfm` object as input ```r summary(topic_model) ``` ``` ## A topic model with 4 topics, 193 documents and a 18703 word dictionary. ``` ``` ## Topic 1 Top Words: ## Highest Prob: captain, nautilus, sea, one, nemo, said, ned ## FREX: nautilus, nemo, ned, conseil, canadian, ocean, submarine ## Lift: deg, nautilus, ned, whale, vanikoro, savages, canadian ## Score: nautilus, nemo, ned, conseil, canadian, ocean, deg ## Topic 2 Top Words: ## Highest Prob: mr, elizabeth, said, mrs, darcy, much, must ## FREX: elizabeth, darcy, bennet, jane, bingley, wickham, collins ## Lift: lucas, jane, bennet, wickham, gardiner, lizzy, collins ## Score: elizabeth, darcy, bennet, bingley, jane, wickham, mr ## Topic 3 Top Words: ## Highest Prob: one, upon, said, people, martians, came, saw ## FREX: martians, martian, woking, mars, curate, pine, ulla ## Lift: seaward, ogilvy, revolver, whip, _thunder, child_, ironclads ## Score: martians, martian, woking, cylinder, mars, curate, ulla ## Topic 4 Top Words: ## Highest Prob: said, joe, mr, one, now, come, know ## FREX: joe, pip, herbert, wemmick, havisham, estella, biddy ## Lift: provis, jaggers's, clara, clem, magwitch, jolly, hulks ## Score: joe, pip, havisham, herbert, estella, biddy, wemmick ``` --- ## **Exploring the output of topic modeling** ```r chapter_topics <- tidy(topic_model, matrix = "beta") chapter_topics ``` ``` ## # A tibble: 74,812 x 3 ## topic term beta ## <int> <chr> <dbl> ## 1 1 joe 2.62e-215 ## 2 2 joe 5.09e- 58 ## 3 3 joe 3.55e-110 ## 4 4 joe 8.91e- 3 ## 5 1 mr 1.50e- 4 ## 6 2 mr 1.44e- 2 ## 7 3 mr 3.41e-108 ## 8 4 mr 8.30e- 3 ## 9 1 biddy 4.63e-227 ## 10 2 biddy 3.71e- 52 ## # … with 74,802 more rows ``` --- ## **Exploring the output of topic modeling** .unscramble[U N S C R A M B L E] ``` top_terms <- chapter_topics %>% ``` ``` ungroup() %>% ``` ``` group_by(topic) %>% ``` ``` arrange(topic, -beta) ``` ``` top_n(10, beta) %>% ``` --- ## **Exploring the output of topic modeling** ```r top_terms <- chapter_topics %>% group_by(topic) %>% top_n(10, beta) %>% ungroup() %>% arrange(topic, -beta) ``` --- ## **Exploring the output of topic modeling** ```r top_terms ``` ``` ## # A tibble: 40 x 3 ## topic term beta ## <int> <chr> <dbl> ## 1 1 captain 0.0120 ## 2 1 nautilus 0.0101 ## 3 1 sea 0.00688 ## 4 1 one 0.00684 ## 5 1 nemo 0.00674 ## 6 1 said 0.00631 ## 7 1 ned 0.00622 ## 8 1 us 0.00585 ## 9 1 conseil 0.00526 ## 10 1 land 0.00472 ## # … with 30 more rows ``` --- ## **Exploring the output of topic modeling** ```r top_terms %>% mutate(term = fct_reorder(term, beta)) %>% * ggplot(aes(term, beta, fill = factor(topic))) + geom_col(show.legend = FALSE) + facet_wrap(~ topic, scales = "free") + coord_flip() ``` --- <!-- --> --- ## **How are documents classified?** ```r chapters_gamma <- tidy(topic_model, matrix = "gamma", document_names = rownames(words_sparse)) chapters_gamma ``` ``` ## # A tibble: 772 x 3 ## document topic gamma ## <chr> <int> <dbl> ## 1 Great Expectations_57 1 0.000180 ## 2 Great Expectations_7 1 0.000185 ## 3 Pride and Prejudice_18 1 0.0000707 ## 4 Great Expectations_17 1 0.000239 ## 5 Great Expectations_27 1 0.000223 ## 6 Great Expectations_38 1 0.000255 ## 7 Great Expectations_2 1 0.000160 ## 8 Great Expectations_19 1 0.000139 ## 9 Great Expectations_23 1 0.000312 ## 10 Great Expectations_11 1 0.000136 ## # … with 762 more rows ``` --- ## **How are documents classified?** .large[What do you predict will happen if we run the following code? 🤔] ```r chapters_parsed <- chapters_gamma %>% separate(document, c("title", "chapter"), sep = "_", convert = TRUE) chapters_parsed ``` --- ## **How are documents classified?** .large[What do you predict will happen if we run the following code? 🤔] ```r chapters_parsed <- chapters_gamma %>% separate(document, c("title", "chapter"), sep = "_", convert = TRUE) glimpse(chapters_parsed) ``` ``` ## Observations: 772 ## Variables: 4 ## $ title <chr> "Great Expectations", "Great Expectations", "Pride and Prejud… ## $ chapter <int> 57, 7, 18, 17, 27, 38, 2, 19, 23, 11, 15, 18, 16, 16, 22, 51,… ## $ topic <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1… ## $ gamma <dbl> 1.795307e-04, 1.850419e-04, 7.074997e-05, 2.393136e-04, 2.232… ``` --- ## **How are documents classified?** .unscramble[U N S C R A M B L E] ``` chapters_parsed %>% ``` ``` ggplot(aes(factor(topic), gamma)) + ``` ``` facet_wrap(~ title) ``` ``` mutate(title = fct_reorder(title, gamma * topic)) %>% ``` ``` geom_boxplot() + ``` --- ## **How are documents classified?** ```r chapters_parsed %>% mutate(title = fct_reorder(title, gamma * topic)) %>% ggplot(aes(factor(topic), gamma)) + geom_boxplot() + facet_wrap(~ title) ``` --- <!-- --> --- class: center, middle, inverse background-image: url(figs/p_and_p_cover.png) background-size: cover # GOING FARTHER 🚀 --- ## Tidying model output ### Which words in each document are assigned to which topics? - .large[`augment()`] - .large[Add information to each observation in the original data] --- background-image: url(figs/stm_video.png) background-size: 850px --- ## **Using stm** - .large[Document-level covariates] ```r topic_model <- stm(words_sparse, K = 0, init.type = "Spectral", prevalence = ~s(Year), data = covariates, verbose = FALSE) ``` - .large[Use functions for `semanticCoherence()`, `checkResiduals()`, `exclusivity()`, and more!] - .large[Check out http://www.structuraltopicmodel.com/] - .large[See [my blog post](https://juliasilge.com/blog/evaluating-stm/) for how to choose `K`, the number of topics] --- background-image: url(figs/model_diagnostic-1.png) background-position: 50% 50% background-size: 950px --- # Stemming? .large[Advice from [Schofield & Mimno](https://mimno.infosci.cornell.edu/papers/schofield_tacl_2016.pdf)] .large["Comparing Apples to Apple: The Effects of Stemmers on Topic Models"] --- class: right, middle <h1 class="fa fa-quote-left fa-fw"></h1> <h2> Despite their frequent use in topic modeling, we find that stemmers produce no meaningful improvement in likelihood and coherence and in fact can degrade topic stability. </h2> <h1 class="fa fa-quote-right fa-fw"></h1> --- ## **Train many topic models** ```r library(furrr) plan(multicore) *many_models <- tibble(K = c(3, 4, 6, 8, 10)) %>% mutate(topic_model = future_map(K, ~stm(words_sparse, K = ., verbose = FALSE))) many_models ``` ``` ## # A tibble: 5 x 2 ## K topic_model ## <dbl> <list> ## 1 3 <STM> ## 2 4 <STM> ## 3 6 <STM> ## 4 8 <STM> ## 5 10 <STM> ``` --- ## **Train many topic models** ```r heldout <- make.heldout(words_sparse) k_result <- many_models %>% mutate(exclusivity = map(topic_model, exclusivity), semantic_coherence = map(topic_model, semanticCoherence, words_sparse), eval_heldout = map(topic_model, eval.heldout, heldout$missing), residual = map(topic_model, checkResiduals, words_sparse), bound = map_dbl(topic_model, function(x) max(x$convergence$bound)), lfact = map_dbl(topic_model, function(x) lfactorial(x$settings$dim$K)), lbound = bound + lfact, iterations = map_dbl(topic_model, function(x) length(x$convergence$bound))) ``` --- ## **Train many topic models** ```r k_result ``` ``` ## # A tibble: 5 x 10 ## K topic_model exclusivity semantic_cohere… eval_heldout residual bound ## <dbl> <list> <list> <list> <list> <list> <dbl> ## 1 3 <STM> <dbl [3]> <dbl [3]> <named list… <named … -1.73e6 ## 2 4 <STM> <dbl [4]> <dbl [4]> <named list… <named … -1.70e6 ## 3 6 <STM> <dbl [6]> <dbl [6]> <named list… <named … -1.69e6 ## 4 8 <STM> <dbl [8]> <dbl [8]> <named list… <named … -1.67e6 ## 5 10 <STM> <dbl [10]> <dbl [10]> <named list… <named … -1.66e6 ## # … with 3 more variables: lfact <dbl>, lbound <dbl>, iterations <dbl> ``` --- ## **Train many topic models** ```r k_result %>% transmute(K, `Lower bound` = lbound, * Residuals = map_dbl(residual, "dispersion"), * `Semantic coherence` = map_dbl(semantic_coherence, mean), * `Held-out likelihood` = map_dbl(eval_heldout, "expected.heldout")) %>% gather(Metric, Value, -K) %>% ggplot(aes(K, Value, color = Metric)) + geom_line() + facet_wrap(~Metric, scales = "free_y") ``` --- <!-- --> --- ## **What is semantic coherence?** - .large[Semantic coherence is maximized when the most probable words in a given topic frequently co-occur together] -- - .large[Correlates well with human judgment of topic quality 😄] -- - .large[Having high semantic coherence is relatively easy, though, if you only have a few topics dominated by very common words 😢] -- - .large[Measure semantic coherence **and** exclusivity] --- ## **Train many topic models** ```r k_result %>% select(K, exclusivity, semantic_coherence) %>% filter(K %in% c(3, 6, 10)) %>% unnest(cols = c(exclusivity, semantic_coherence)) %>% ggplot(aes(semantic_coherence, exclusivity, color = factor(K))) + geom_point() ``` --- <!-- --> --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Topic modeling is an example of...] - .unscramble[supervised machine learning] - .unscramble[unsupervised machine learning] --- class: right, middle, inverse background-image: url(figs/p_and_p_cover.png) background-size: cover # TEXT CLASSIFICATION <h1 class="fa fa-balance-scale fa-fw"></h1> --- ## **Downloading your text data** ```r library(tidyverse) library(gutenbergr) titles <- c("The War of the Worlds", "Pride and Prejudice") books <- gutenberg_works(title %in% titles) %>% gutenberg_download(meta_fields = "title") %>% mutate(document = row_number()) glimpse(books) ``` ``` ## Observations: 19,504 ## Variables: 4 ## $ gutenberg_id <int> 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, … ## $ text <chr> "The War of the Worlds", "", "by H. G. Wells [1898]", ""… ## $ title <chr> "The War of the Worlds", "The War of the Worlds", "The W… ## $ document <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1… ``` --- ## **Making a tidy dataset** .large[Use this kind of data structure for EDA! 💅] ```r library(tidytext) tidy_books <- books %>% * unnest_tokens(word, text) %>% group_by(word) %>% filter(n() > 10) %>% ungroup glimpse(tidy_books) ``` ``` ## Observations: 159,707 ## Variables: 4 ## $ gutenberg_id <int> 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, … ## $ title <chr> "The War of the Worlds", "The War of the Worlds", "The W… ## $ document <int> 1, 1, 1, 1, 3, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7,… ## $ word <chr> "the", "war", "of", "the", "by", "but", "who", "shall", … ``` --- ## **Create training and testing sets** .large[What do you predict will happen if we run the following code? 🤔] ```r library(rsample) books_split <- tidy_books %>% distinct(document) %>% * initial_split() train_data <- training(books_split) test_data <- testing(books_split) ``` --- ## **Cast to a sparse matrix** ```r sparse_words <- tidy_books %>% count(document, word, sort = TRUE) %>% inner_join(train_data) %>% * cast_sparse(document, word, n) class(sparse_words) ``` ``` ## [1] "dgCMatrix" ## attr(,"package") ## [1] "Matrix" ``` ```r dim(sparse_words) ``` ``` ## [1] 12039 1652 ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Which `dim` of the sparse matrix is the number of features?] - .large[12039] - .large[1652] .large[Feature = term = word] --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[If you want to use tf-idf instead of counts, should you calculate tf-idf before or after splitting train and test?] - .large[Before] - .large[After] --- ## **Build a dataframe with the response variable** ```r word_rownames <- as.integer(rownames(sparse_words)) books_joined <- tibble(document = word_rownames) %>% left_join(books %>% select(document, title)) glimpse(books_joined) ``` ``` ## Observations: 12,039 ## Variables: 2 ## $ document <int> 4532, 6450, 15669, 308, 1264, 1287, 1698, 1897, 2135, 2161, … ## $ title <chr> "The War of the Worlds", "The War of the Worlds", "Pride and… ``` --- ## **Train a glmnet model** ```r library(glmnet) library(doMC) registerDoMC(cores = 8) is_jane <- books_joined$title == "Pride and Prejudice" model <- cv.glmnet(sparse_words, is_jane, family = "binomial", parallel = TRUE, keep = TRUE) ``` - .large[Regularization constrains magnitude of coefficients] - .large[LASSO performs feature selection] --- ## **Tidying our model** .large[Tidy, then filter to choose some lambda from glmnet output] ```r library(broom) coefs <- model$glmnet.fit %>% tidy() %>% filter(lambda == model$lambda.1se) Intercept <- coefs %>% filter(term == "(Intercept)") %>% pull(estimate) ``` --- ## **Tidying our model** .unscramble[U N S C R A M B L E] ``` classifications <- tidy_books %>% ``` ``` mutate(probability = plogis(Intercept + score)) ``` ``` inner_join(test_data) %>% ``` ``` group_by(document) %>% ``` ``` inner_join(coefs, by = c("word" = "term")) %>% ``` ``` summarize(score = sum(estimate)) %>% ``` --- ## **Tidying our model** ```r classifications <- tidy_books %>% inner_join(test_data) %>% inner_join(coefs, by = c("word" = "term")) %>% group_by(document) %>% summarize(score = sum(estimate)) %>% mutate(probability = plogis(Intercept + score)) glimpse(classifications) ``` ``` ## Observations: 3,992 ## Variables: 3 ## $ document <int> 1, 6, 7, 28, 29, 33, 34, 37, 45, 50, 51, 52, 53, 55, 60, … ## $ score <dbl> -2.2303223, 2.0101769, -1.1689632, -1.7574498, -2.2689393… ## $ probability <dbl> 0.122328656, 0.906356553, 0.287163207, 0.182770543, 0.118… ``` --- ## **Understanding our model** .unscramble[U N S C R A M B L E] ``` coefs %>% ``` ``` group_by(estimate > 0) %>% ``` ``` coord_flip() ``` ``` geom_col(show.legend = FALSE) + ``` ``` ungroup %>% ``` ``` top_n(10, abs(estimate)) %>% ``` ``` ggplot(aes(fct_reorder(term, estimate), estimate, fill = estimate > 0)) + ``` --- ## **Understanding our model** ```r coefs %>% group_by(estimate > 0) %>% top_n(10, abs(estimate)) %>% ungroup %>% ggplot(aes(fct_reorder(term, estimate), estimate, fill = estimate > 0)) + geom_col(show.legend = FALSE) + coord_flip() ``` --- 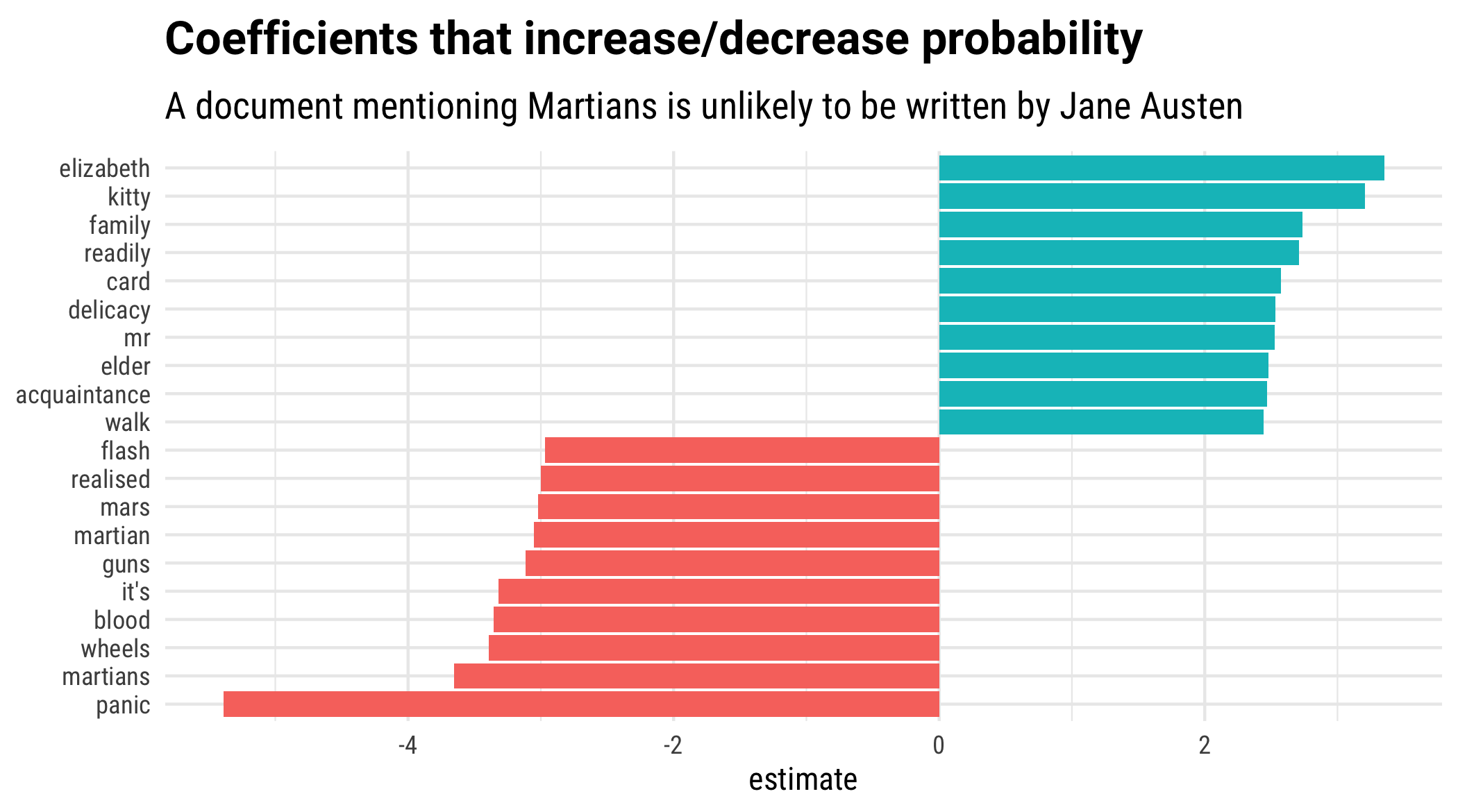<!-- --> --- ## **ROC** .large[What do you predict will happen if we run the following code? 🤔] ```r comment_classes <- classifications %>% left_join(books %>% select(title, document), by = "document") %>% mutate(title = as.factor(title)) comment_classes ``` --- ## **ROC** .large[What do you predict will happen if we run the following code? 🤔] ```r comment_classes <- classifications %>% left_join(books %>% select(title, document), by = "document") %>% mutate(title = as.factor(title)) glimpse(comment_classes) ``` ``` ## Observations: 3,992 ## Variables: 4 ## $ document <int> 1, 6, 7, 28, 29, 33, 34, 37, 45, 50, 51, 52, 53, 55, 60, … ## $ score <dbl> -2.2303223, 2.0101769, -1.1689632, -1.7574498, -2.2689393… ## $ probability <dbl> 0.122328656, 0.906356553, 0.287163207, 0.182770543, 0.118… ## $ title <fct> The War of the Worlds, The War of the Worlds, The War of … ``` --- ## **ROC** ```r library(yardstick) comment_classes %>% * roc_curve(title, probability) %>% ggplot(aes(x = 1 - specificity, y = sensitivity)) + geom_line(size = 1.5) + geom_abline( lty = 2, alpha = 0.5, color = "gray50", size = 1.2 ) ``` --- <!-- --> --- ## **AUC for model** ```r comment_classes %>% roc_auc(title, probability) ``` ``` ## # A tibble: 1 x 3 ## .metric .estimator .estimate ## <chr> <chr> <dbl> ## 1 roc_auc binary 0.973 ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Is this the AUC for the training or testing data?] - .large[Training] - .large[Testing] --- ## **Confusion matrix** ```r comment_classes %>% mutate( prediction = case_when( probability > 0.5 ~ "Pride and Prejudice", TRUE ~ "The War of the Worlds" ), prediction = as.factor(prediction) ) %>% * conf_mat(title, prediction) ``` ``` ## Truth ## Prediction Pride and Prejudice The War of the Worlds ## Pride and Prejudice 2511 182 ## The War of the Worlds 141 1158 ``` --- ## **Misclassifications** Let's talk about misclassifications. Which documents here were incorrectly predicted to be written by Jane Austen? ```r comment_classes %>% * filter(probability > .8, title == "The War of the Worlds") %>% sample_n(5) %>% inner_join(books %>% select(document, text)) %>% select(probability, text) ``` ``` ## # A tibble: 5 x 2 ## probability text ## <dbl> <chr> ## 1 0.803 torrent of half-sane and always frothy repentance for his vacant … ## 2 0.903 ladies there being by no means the least active. ## 3 0.862 and all that is necessary for the support of animated existence. ## 4 0.968 evening paper, after wiring for authentication from him and recei… ## 5 0.991 turned hastily to his own room, put all his available money--some… ``` --- ## **Misclassifications** Let's talk about misclassifications. Which documents here were incorrectly predicted to *not* be written by Jane Austen? ```r comment_classes %>% * filter(probability < .3, title == "Pride and Prejudice" ) %>% sample_n(5) %>% inner_join(books %>% select(document, text)) %>% select(probability, text) ``` ``` ## # A tibble: 5 x 2 ## probability text ## <dbl> <chr> ## 1 0.157 "\"I know them a little. Their brother is a pleasant gentlemanlik… ## 2 0.239 "man about them, that he advanced but little. Whilst wandering on… ## 3 0.0312 "foxhounds, and drink a bottle of wine a day.\"" ## 4 0.214 "At five o'clock the two ladies retired to dress, and at half-pas… ## 5 0.175 "into his own hands." ``` --- background-image: url(figs/tmwr_0601.png) background-position: 50% 70% background-size: 750px ## **Workflow for text mining/modeling** --- background-image: url(figs/lizzieskipping.gif) background-position: 50% 55% background-size: 750px # **Go explore real-world text!** --- class: left, middle <img src="figs/blue_jane.png" width="150px"/> # Thanks! <a href="http://twitter.com/juliasilge"><i class="fa fa-twitter fa-fw"></i> @juliasilge</a><br> <a href="http://github.com/juliasilge"><i class="fa fa-github fa-fw"></i> @juliasilge</a><br> <a href="https://juliasilge.com"><i class="fa fa-link fa-fw"></i> juliasilge.com</a><br> <a href="https://tidytextmining.com"><i class="fa fa-book fa-fw"></i> tidytextmining.com</a><br> <a href="mailto:julia.silge@gmail.com"><i class="fa fa-paper-plane fa-fw"></i> julia.silge@gmail.com</a> Slides created with [**remark.js**](http://remarkjs.com/) and the R package [**xaringan**](https://github.com/yihui/xaringan) --- class: middle, center # <i class="fa fa-check-circle"></i> # Submit feedback before you leave .large[[rstd.io/ws-survey](https://rstd.io/ws-survey)]