layout: true <div class="my-footer"><span>bit.ly/silge-rstudioconf-1</span></div> --- class: inverse, center, bottom background-image: url(figs/robert-bye-R-WtV-QyVnY-unsplash.jpg) background-size: cover # WELCOME! ### Text Mining Using Tidy Data Principles --- class: inverse, center, middle background-image: url(figs/p_and_p_cover.png) background-size: cover # Text Mining <img src="figs/blue_jane.png" width="150px"/> ### USING TIDY PRINCIPLES .large[Julia Silge | rstudio::conf | 27 Jan 2020] --- class: middle, center .pull-left[ # <i class="fa fa-wifi"></i> Wifi network name .large[rstudio20] ] .pull-left[ # <i class="fa fa-key"></i> Wifi password .large[tidyverse20] ] --- <img src="figs/blue_jane.png" style="position:absolute;top:30px;right:30px;" width="100px"/> ## **Workshop policies** -- - .large[Identify the exits closest to you in case of emergency] -- - .large[Please review the rstudio::conf code of conduct that applies to all workshops] -- - .large[CoC issues can be addressed three ways:] - In person: contact any rstudio::conf staff member or the conference registration desk - By email: send a message to `conf@rstudio.com` - By phone: call 844-448-1212 -- - .large[Please do not photograph people wearing red lanyards] -- - .large[A chill-out room is available for neurologically diverse attendees on the 4th floor of tower 1] --- class: right, middle <img src="figs/blue_jane.png" width="150px"/> # Find me at... <a href="http://twitter.com/juliasilge"><i class="fa fa-twitter fa-fw"></i> @juliasilge</a><br> <a href="http://github.com/juliasilge"><i class="fa fa-github fa-fw"></i> @juliasilge</a><br> <a href="https://juliasilge.com"><i class="fa fa-link fa-fw"></i> juliasilge.com</a><br> <a href="https://tidytextmining.com"><i class="fa fa-book fa-fw"></i> tidytextmining.com</a><br> <a href="mailto:julia.silge@gmail.com"><i class="fa fa-paper-plane fa-fw"></i> julia.silge@gmail.com</a> --- class: left, top <img src="figs/blue_jane.png" width="150px"/> # Meet your TAs ## 💫 Emil Hvitfelt (coordinator) ## 💥 Jeroen Claes ## ✨ Kasia Kulma --- class: left, top <img src="figs/blue_jane.png" width="150px"/> # Asking for help -- ## 🆘 "I'm stuck" -- ## ⚠️ "I'm not stuck, but I need help on my computer" -- ## 🙋 "I need help understanding something" --- class: inverse ## Text in the real world -- - .large[Text data is increasingly important 📚] -- - .large[NLP training is scarce on the ground 😱] --- background-image: url(figs/vexing.gif) background-position: 50% 50% background-size: 650px --- background-image: url(figs/p_and_p_cover.png) background-size: cover class: inverse, center, middle # TIDY DATA PRINCIPLES + TEXT MINING = 🎉 --- background-image: url(figs/tidytext_repo.png) background-size: 800px background-position: 50% 20% class: bottom, right .large[[https://github.com/juliasilge/tidytext](https://github.com/juliasilge/tidytext)] .large[[https://tidytextmining.com/](https://tidytextmining.com/)] --- background-image: url(figs/cover.png) background-size: 450px background-position: 50% 50% --- class: middle, center # <i class="fa fa-github"></i> # GitHub repo for workshop: .large[[rstd.io/conf20-tidytext](https://rstd.io/conf20-tidytext)] --- class: inverse ## Plan for this workshop -- - .large[EDA for text *today*] -- - .large[Modeling for text *tomorrow*] -- - .large[Log in to RStudio Cloud 💻] -- - .large[Introduce yourself to your neighbors 👋] --- class: middle, center # <i class="fa fa-cloud"></i> # Go here and log in (free): .large[[bit.ly/rstudio-text-course](http://bit.ly/rstudio-text-course)] --- ## Let's install some packages ```r install.packages(c("tidyverse", "tidytext", "gutenbergr")) ``` --- <img src="figs/purple_emily.png" style="position:absolute;top:20px;right:20px;" width="100px"/> ## **What do we mean by tidy text?** ```r text <- c("Tell all the truth but tell it slant —", "Success in Circuit lies", "Too bright for our infirm Delight", "The Truth's superb surprise", "As Lightning to the Children eased", "With explanation kind", "The Truth must dazzle gradually", "Or every man be blind —") text ``` ``` ## [1] "Tell all the truth but tell it slant —" ## [2] "Success in Circuit lies" ## [3] "Too bright for our infirm Delight" ## [4] "The Truth's superb surprise" ## [5] "As Lightning to the Children eased" ## [6] "With explanation kind" ## [7] "The Truth must dazzle gradually" ## [8] "Or every man be blind —" ``` --- <img src="figs/purple_emily.png" style="position:absolute;top:20px;right:20px;" width="100px"/> ## **What do we mean by tidy text?** ```r library(tidyverse) text_df <- tibble(line = 1:8, text = text) text_df ``` ``` ## # A tibble: 8 x 2 ## line text ## <int> <chr> ## 1 1 Tell all the truth but tell it slant — ## 2 2 Success in Circuit lies ## 3 3 Too bright for our infirm Delight ## 4 4 The Truth's superb surprise ## 5 5 As Lightning to the Children eased ## 6 6 With explanation kind ## 7 7 The Truth must dazzle gradually ## 8 8 Or every man be blind — ``` --- <img src="figs/purple_emily.png" style="position:absolute;top:20px;right:20px;" width="100px"/> ## **What do we mean by tidy text?** ```r library(tidytext) text_df %>% * unnest_tokens(word, text) ``` ``` ## # A tibble: 41 x 2 ## line word ## <int> <chr> ## 1 1 tell ## 2 1 all ## 3 1 the ## 4 1 truth ## 5 1 but ## 6 1 tell ## 7 1 it ## 8 1 slant ## 9 2 success ## 10 2 in ## # … with 31 more rows ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[A tidy text dataset typically has] - .unscramble[more] - .unscramble[fewer] .large[rows than the original, non-tidy text dataset.] --- ## **Gathering more data** .large[You can access the full text of many public domain works from [Project Gutenberg](https://www.gutenberg.org/) using the [gutenbergr](https://ropensci.org/tutorials/gutenbergr_tutorial.html) package.] ```r library(gutenbergr) full_text <- gutenberg_download(1342) ``` .large[What book do *you* want to analyze today? 📖 👯♂️ 📖] --- ## **Time to tidy your text!** ```r tidy_book <- full_text %>% mutate(line = row_number()) %>% * unnest_tokens(word, text) glimpse(tidy_book) ``` ``` ## Observations: 122,204 ## Variables: 3 ## $ gutenberg_id <int> 1342, 1342, 1342, 1342, 1342, 1342, 1342, 1342, 1342, 13… ## $ line <int> 1, 1, 1, 3, 3, 3, 7, 7, 10, 10, 10, 10, 10, 10, 10, 10, … ## $ word <chr> "pride", "and", "prejudice", "by", "jane", "austen", "ch… ``` --- ## **What are the most common words?** .large[What do you predict will happen if we run the following code? 🤔] ```r tidy_book %>% count(word, sort = TRUE) ``` --- ## **What are the most common words?** .large[What do you predict will happen if we run the following code? 🤔] ```r tidy_book %>% count(word, sort = TRUE) ``` ``` ## # A tibble: 6,538 x 2 ## word n ## <chr> <int> ## 1 the 4331 ## 2 to 4162 ## 3 of 3610 ## 4 and 3585 ## 5 her 2203 ## 6 i 2065 ## 7 a 1954 ## 8 in 1880 ## 9 was 1843 ## 10 she 1695 ## # … with 6,528 more rows ``` --- background-image: url(figs/stop.gif) background-size: 500px background-position: 50% 50% ## **Stop words** --- ## **Stop words** ```r get_stopwords() ``` ``` ## # A tibble: 175 x 2 ## word lexicon ## <chr> <chr> ## 1 i snowball ## 2 me snowball ## 3 my snowball ## 4 myself snowball ## 5 we snowball ## 6 our snowball ## 7 ours snowball ## 8 ourselves snowball ## 9 you snowball ## 10 your snowball ## # … with 165 more rows ``` --- ## **Stop words** ```r get_stopwords(language = "es") ``` ``` ## # A tibble: 308 x 2 ## word lexicon ## <chr> <chr> ## 1 de snowball ## 2 la snowball ## 3 que snowball ## 4 el snowball ## 5 en snowball ## 6 y snowball ## 7 a snowball ## 8 los snowball ## 9 del snowball ## 10 se snowball ## # … with 298 more rows ``` --- ## **Stop words** ```r get_stopwords(language = "pt") ``` ``` ## # A tibble: 203 x 2 ## word lexicon ## <chr> <chr> ## 1 de snowball ## 2 a snowball ## 3 o snowball ## 4 que snowball ## 5 e snowball ## 6 do snowball ## 7 da snowball ## 8 em snowball ## 9 um snowball ## 10 para snowball ## # … with 193 more rows ``` --- ## **Stop words** ```r get_stopwords(source = "smart") ``` ``` ## # A tibble: 571 x 2 ## word lexicon ## <chr> <chr> ## 1 a smart ## 2 a's smart ## 3 able smart ## 4 about smart ## 5 above smart ## 6 according smart ## 7 accordingly smart ## 8 across smart ## 9 actually smart ## 10 after smart ## # … with 561 more rows ``` --- ## **What are the most common words?** .unscramble[U N S C R A M B L E] ``` anti_join(get_stopwords(source = "smart")) %>% ``` ``` tidy_book %>% ``` ``` count(word, sort = TRUE) %>% ``` ``` coord_flip() ``` ``` geom_col() + ``` ``` top_n(20) %>% ``` ``` ggplot(aes(fct_reorder(word, n), n)) + ``` --- ## **What are the most common words?** ```r tidy_book %>% anti_join(get_stopwords(source = "smart")) %>% count(word, sort = TRUE) %>% top_n(20) %>% * ggplot(aes(fct_reorder(word, n), n)) + geom_col() + coord_flip() ``` --- 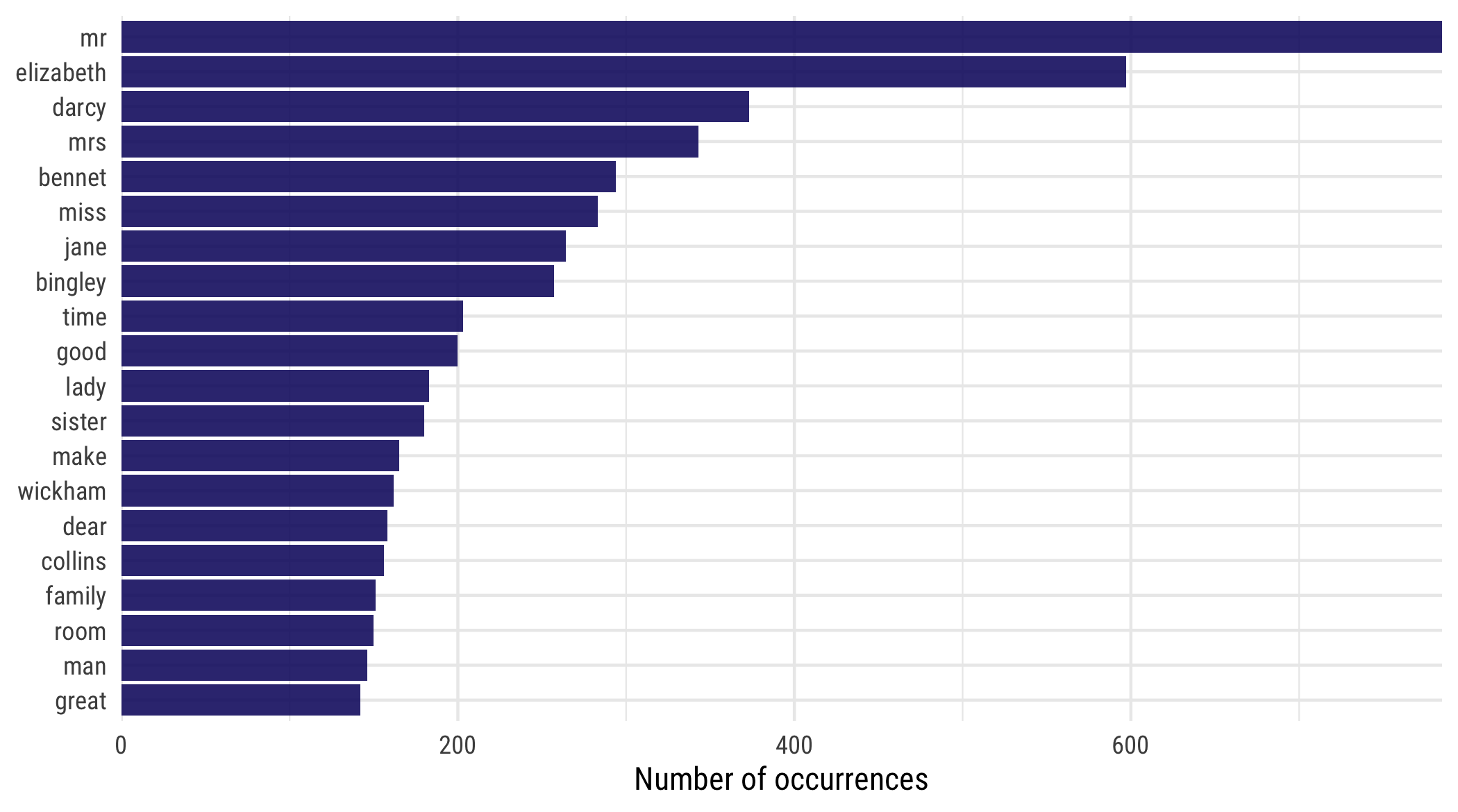<!-- --> --- background-image: url(figs/tilecounts-1.png) background-size: 700px --- background-image: url(figs/tilerate-1.png) background-size: 700px --- background-image: url(figs/p_and_p_cover.png) background-size: cover class: inverse, center, middle ## SENTIMENT ANALYSIS 😄 😢 😠 --- ## **Sentiment lexicons** ```r get_sentiments("afinn") ``` ``` ## # A tibble: 2,477 x 2 ## word value ## <chr> <dbl> ## 1 abandon -2 ## 2 abandoned -2 ## 3 abandons -2 ## 4 abducted -2 ## 5 abduction -2 ## 6 abductions -2 ## 7 abhor -3 ## 8 abhorred -3 ## 9 abhorrent -3 ## 10 abhors -3 ## # … with 2,467 more rows ``` --- ## **Sentiment lexicons** ```r get_sentiments("bing") ``` ``` ## # A tibble: 6,786 x 2 ## word sentiment ## <chr> <chr> ## 1 2-faces negative ## 2 abnormal negative ## 3 abolish negative ## 4 abominable negative ## 5 abominably negative ## 6 abominate negative ## 7 abomination negative ## 8 abort negative ## 9 aborted negative ## 10 aborts negative ## # … with 6,776 more rows ``` --- ## **Sentiment lexicons** ```r get_sentiments("nrc") ``` ``` ## # A tibble: 13,901 x 2 ## word sentiment ## <chr> <chr> ## 1 abacus trust ## 2 abandon fear ## 3 abandon negative ## 4 abandon sadness ## 5 abandoned anger ## 6 abandoned fear ## 7 abandoned negative ## 8 abandoned sadness ## 9 abandonment anger ## 10 abandonment fear ## # … with 13,891 more rows ``` --- ## **Sentiment lexicons** ```r get_sentiments("loughran") ``` ``` ## # A tibble: 4,150 x 2 ## word sentiment ## <chr> <chr> ## 1 abandon negative ## 2 abandoned negative ## 3 abandoning negative ## 4 abandonment negative ## 5 abandonments negative ## 6 abandons negative ## 7 abdicated negative ## 8 abdicates negative ## 9 abdicating negative ## 10 abdication negative ## # … with 4,140 more rows ``` --- ## **Implementing sentiment analysis** ```r tidy_book %>% * inner_join(get_sentiments("bing")) %>% count(sentiment, sort = TRUE) ``` ``` ## # A tibble: 2 x 2 ## sentiment n ## <chr> <int> ## 1 positive 5052 ## 2 negative 3652 ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[What kind of join is appropriate for sentiment analysis?] - .large[`anti_join()`] - .large[`full_join()`] - .large[`outer_join()`] - .large[`inner_join()`] --- ## **Implementing sentiment analysis** .large[What do you predict will happen if we run the following code? 🤔] ```r tidy_book %>% inner_join(get_sentiments("bing")) %>% * count(sentiment, word, sort = TRUE) ``` --- ## **Implementing sentiment analysis** .large[What do you predict will happen if we run the following code? 🤔] ```r tidy_book %>% inner_join(get_sentiments("bing")) %>% * count(sentiment, word, sort = TRUE) ``` ``` ## # A tibble: 1,430 x 3 ## sentiment word n ## <chr> <chr> <int> ## 1 negative miss 283 ## 2 positive well 224 ## 3 positive good 200 ## 4 positive great 142 ## 5 positive enough 106 ## 6 positive better 92 ## 7 positive love 92 ## 8 positive pleasure 92 ## 9 positive happy 83 ## 10 positive like 77 ## # … with 1,420 more rows ``` --- ## **Implementing sentiment analysis** ```r tidy_book %>% inner_join(get_sentiments("bing")) %>% count(sentiment, word, sort = TRUE) %>% group_by(sentiment) %>% top_n(10) %>% ungroup %>% * ggplot(aes(fct_reorder(word, n), n, fill = sentiment)) + geom_col() + coord_flip() + facet_wrap(~ sentiment, scales = "free") ``` --- class: middle 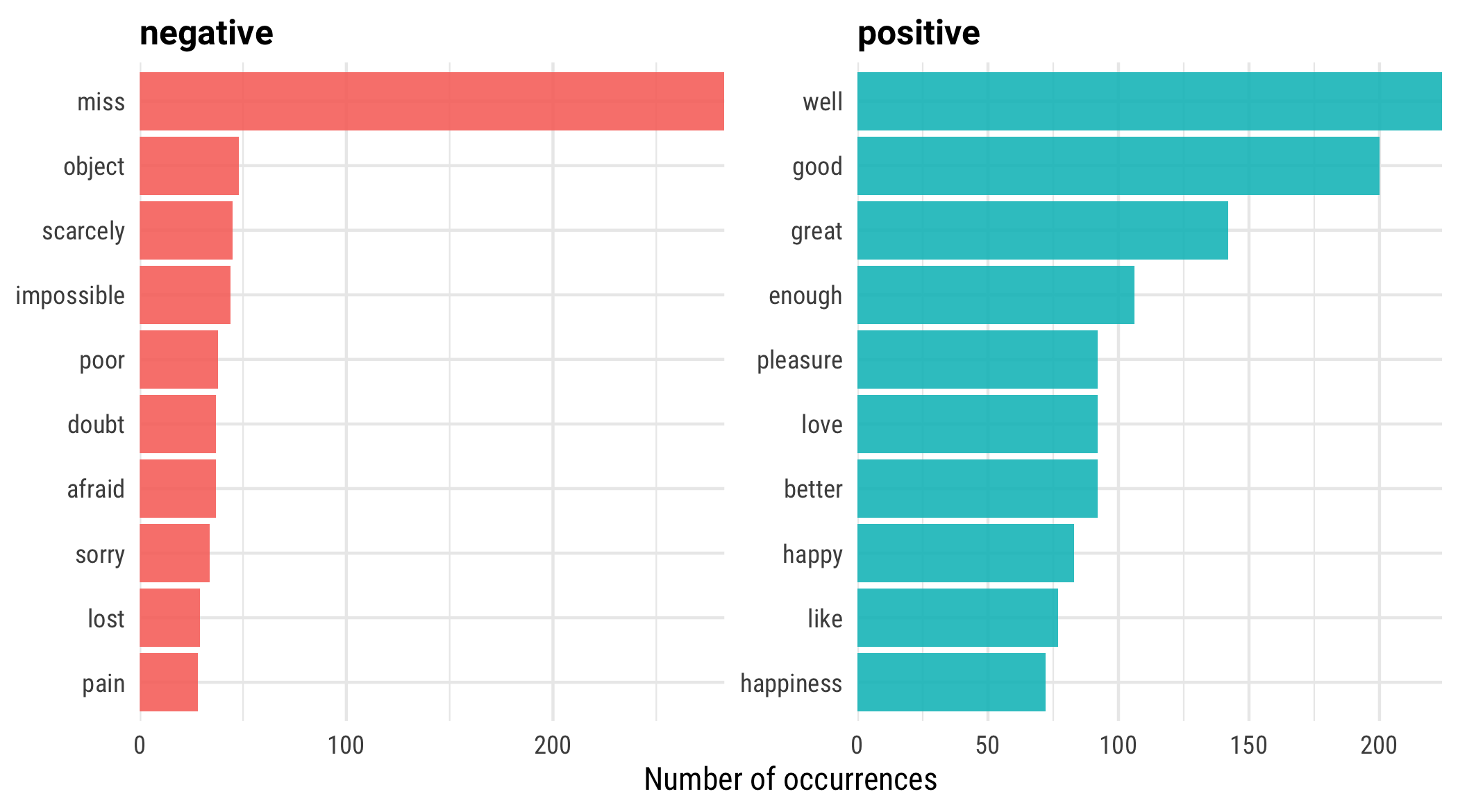<!-- --> --- background-image: url(figs/p_and_p_cover.png) background-size: cover class: inverse, center, middle ## WHAT IS A DOCUMENT ABOUT? 🤔 --- ## **What is a document about?** - .large[Term frequency] - .large[Inverse document frequency] `$$idf(\text{term}) = \ln{\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}}\right)}$$` ### tf-idf is about comparing **documents** within a **collection**. --- ## **Understanding tf-idf** .large[Make a collection (*corpus*) for yourself! 💅] ```r full_collection <- gutenberg_download(c(1342, 158, 161, 141), meta_fields = "title") ``` --- ## **Understanding tf-idf** .large[Make a collection (*corpus*) for yourself! 💅] ```r full_collection ``` ``` ## # A tibble: 57,238 x 3 ## gutenberg_id text title ## <int> <chr> <chr> ## 1 141 "MANSFIELD PARK" Mansfield Park ## 2 141 "" Mansfield Park ## 3 141 "(1814)" Mansfield Park ## 4 141 "" Mansfield Park ## 5 141 "" Mansfield Park ## 6 141 "By Jane Austen" Mansfield Park ## 7 141 "" Mansfield Park ## 8 141 "" Mansfield Park ## 9 141 "" Mansfield Park ## 10 141 "" Mansfield Park ## # … with 57,228 more rows ``` --- ## **Counting word frequencies in your collection** ```r book_words <- full_collection %>% * unnest_tokens(word, text) %>% count(title, word, sort = TRUE) ``` What do the columns of `book_words` tell us? --- ## **Calculating tf-idf** ```r book_tfidf <- book_words %>% * bind_tf_idf(word, title, n) ``` --- ## **Calculating tf-idf** .large[That's... super exciting???] ```r book_tfidf ``` ``` ## # A tibble: 28,389 x 6 ## title word n tf idf tf_idf ## <chr> <chr> <int> <dbl> <dbl> <dbl> ## 1 Mansfield Park the 6206 0.0387 0 0 ## 2 Mansfield Park to 5475 0.0341 0 0 ## 3 Mansfield Park and 5438 0.0339 0 0 ## 4 Emma to 5239 0.0325 0 0 ## 5 Emma the 5201 0.0323 0 0 ## 6 Emma and 4896 0.0304 0 0 ## 7 Mansfield Park of 4778 0.0298 0 0 ## 8 Pride and Prejudice the 4331 0.0354 0 0 ## 9 Emma of 4291 0.0267 0 0 ## 10 Pride and Prejudice to 4162 0.0341 0 0 ## # … with 28,379 more rows ``` --- ## **Calculating tf-idf** .large[What do you predict will happen if we run the following code? 🤔] ```r book_tfidf %>% arrange(-tf_idf) ``` --- ## **Calculating tf-idf** .large[What do you predict will happen if we run the following code? 🤔] ```r book_tfidf %>% arrange(-tf_idf) ``` ``` ## # A tibble: 28,389 x 6 ## title word n tf idf tf_idf ## <chr> <chr> <int> <dbl> <dbl> <dbl> ## 1 Sense and Sensibility elinor 623 0.00519 1.39 0.00720 ## 2 Emma emma 786 0.00488 1.39 0.00677 ## 3 Sense and Sensibility marianne 492 0.00410 1.39 0.00569 ## 4 Mansfield Park crawford 493 0.00307 1.39 0.00426 ## 5 Pride and Prejudice darcy 373 0.00305 1.39 0.00423 ## 6 Mansfield Park fanny 816 0.00509 0.693 0.00352 ## 7 Pride and Prejudice elizabeth 597 0.00489 0.693 0.00339 ## 8 Emma weston 389 0.00242 1.39 0.00335 ## 9 Pride and Prejudice bennet 294 0.00241 1.39 0.00334 ## 10 Mansfield Park edmund 364 0.00227 1.39 0.00314 ## # … with 28,379 more rows ``` --- ## **Calculating tf-idf** .unscramble[U N S C R A M B L E] ``` group_by(title) %>% ``` ``` book_tfidf %>% ``` ``` top_n(10) %>% ``` ``` ggplot(aes(fct_reorder(word, tf_idf), tf_idf, fill = title)) + ``` ``` facet_wrap(~title, scales = "free") ``` ``` ungroup %>% ``` ``` geom_col(show.legend = FALSE) + ``` ``` coord_flip() + ``` --- ## **Calculating tf-idf** ```r book_tfidf %>% group_by(title) %>% top_n(10) %>% ungroup %>% * ggplot(aes(fct_reorder(word, tf_idf), tf_idf, fill = title)) + geom_col(show.legend = FALSE) + coord_flip() + facet_wrap(~title, scales = "free") ``` --- 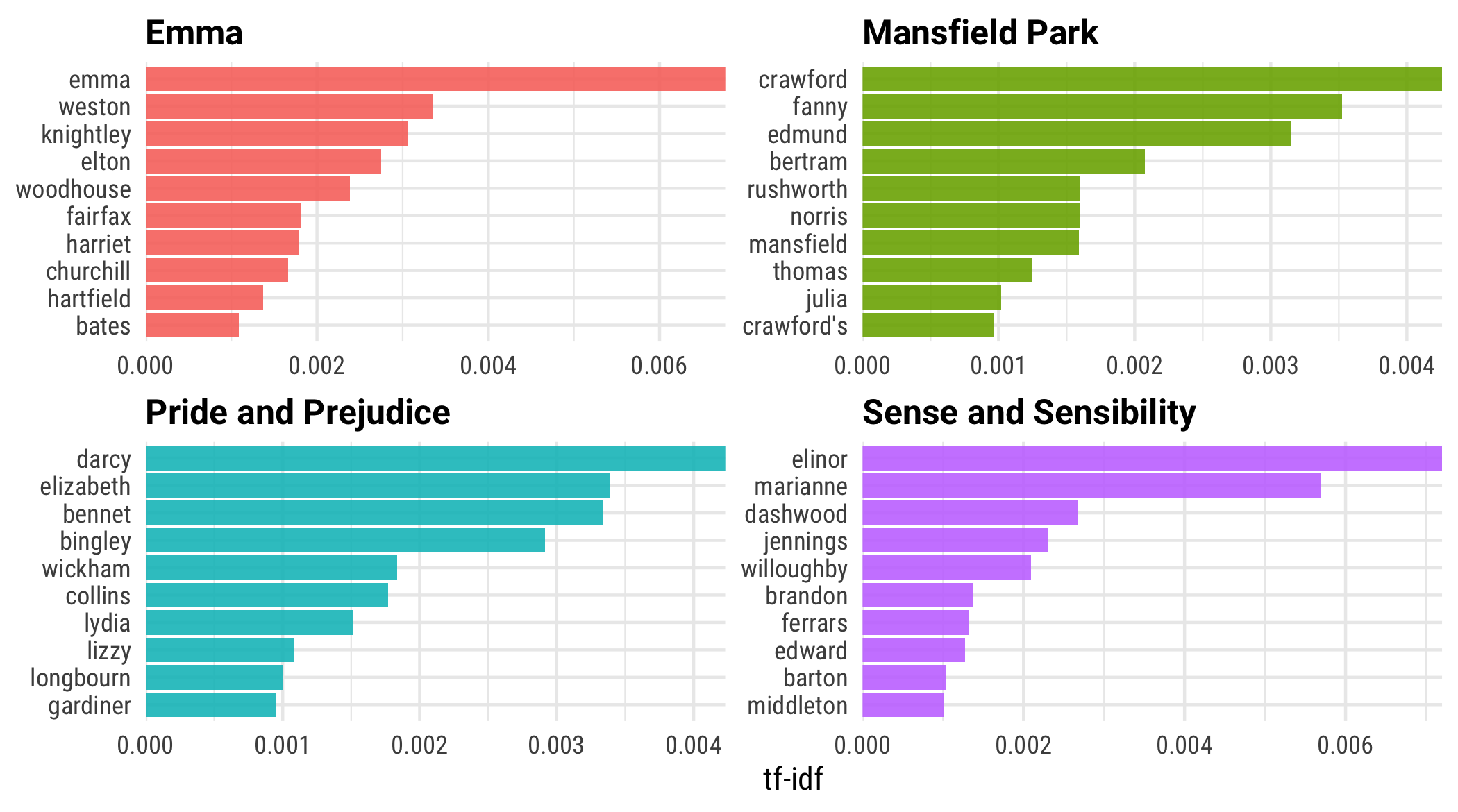<!-- --> --- background-image: url(figs/plot_tf_idf-1.png) background-size: 800px --- ## **N-grams... and beyond!** 🚀 ```r tidy_ngram <- full_text %>% * unnest_tokens(bigram, text, token = "ngrams", n = 2) tidy_ngram ``` ``` ## # A tibble: 122,203 x 2 ## gutenberg_id bigram ## <int> <chr> ## 1 1342 pride and ## 2 1342 and prejudice ## 3 1342 prejudice by ## 4 1342 by jane ## 5 1342 jane austen ## 6 1342 austen chapter ## 7 1342 chapter 1 ## 8 1342 1 it ## 9 1342 it is ## 10 1342 is a ## # … with 122,193 more rows ``` --- ## **N-grams... and beyond!** 🚀 ```r tidy_ngram %>% count(bigram, sort = TRUE) ``` ``` ## # A tibble: 54,998 x 2 ## bigram n ## <chr> <int> ## 1 of the 464 ## 2 to be 443 ## 3 in the 382 ## 4 i am 302 ## 5 of her 260 ## 6 to the 252 ## 7 it was 251 ## 8 mr darcy 243 ## 9 of his 234 ## 10 she was 209 ## # … with 54,988 more rows ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Can we use an `anti_join()` right away to remove stop words?] - .large[Yes! ✅] - .large[No 🙍] --- ## **N-grams... and beyond!** 🚀 ```r bigram_counts <- tidy_ngram %>% * separate(bigram, c("word1", "word2"), sep = " ") %>% filter(!word1 %in% stop_words$word, !word2 %in% stop_words$word) %>% count(word1, word2, sort = TRUE) ``` --- ## **N-grams... and beyond!** 🚀 ```r bigram_counts ``` ``` ## # A tibble: 5,922 x 3 ## word1 word2 n ## <chr> <chr> <int> ## 1 lady catherine 100 ## 2 miss bingley 72 ## 3 miss bennet 60 ## 4 sir william 38 ## 5 de bourgh 35 ## 6 miss darcy 34 ## 7 colonel forster 26 ## 8 colonel fitzwilliam 25 ## 9 cried elizabeth 24 ## 10 miss lucas 23 ## # … with 5,912 more rows ``` --- background-image: url(figs/p_and_p_cover.png) background-size: cover class: inverse ## What can you do with n-grams? - .large[tf-idf of n-grams] -- - .large[network analysis] -- - .large[negation] --- background-image: url(figs/austen-1.png) background-size: 750px --- background-image: url(figs/slider.gif) background-position: 50% 70% ## **What can you do with n-grams?** ### [She Giggles, He Gallops](https://pudding.cool/2017/08/screen-direction/) --- background-image: url(figs/change_overall-1.svg) background-size: contain background-position: center --- ## **Let's install some packages** ```r install.packages(c("widyr", "igraph", "ggraph")) ``` ```r library(widyr) library(igraph) library(ggraph) ``` --- ## **Network analysis** ```r bigram_graph <- bigram_counts %>% filter(n > 5) %>% * graph_from_data_frame() bigram_graph ``` ``` ## IGRAPH 100904d DN-- 48 45 -- ## + attr: name (v/c), n (e/n) ## + edges from 100904d (vertex names): ## [1] lady ->catherine miss ->bingley miss ->bennet ## [4] sir ->william de ->bourgh miss ->darcy ## [7] colonel ->forster colonel ->fitzwilliam cried ->elizabeth ## [10] miss ->lucas miss ->de thousand ->pounds ## [13] lady ->lucas replied ->elizabeth lady ->catherine's ## [16] dear ->lizzy miss ->bingley's catherine ->de ## [19] miss ->elizabeth ten ->thousand dear ->sir ## [22] gracechurch->street miss ->eliza charlotte ->lucas ## + ... omitted several edges ``` --- <img src="figs/blue_jane.png" width="150px"/> ## Jane wants to know... .large[Is `bigram_graph` a tidy dataset?] - .large[Yes ✅] - .large[No 🚫] --- ## **Network analysis** ```r bigram_graph %>% ggraph(layout = "nicely") + * geom_edge_link(aes(edge_alpha = n)) + * geom_node_text(aes(label = name)) + theme_graph() ``` --- ## **Network analysis** ```r bigram_graph %>% ggraph(layout = "nicely") + * geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = arrow(length = unit(1.5, 'mm')), start_cap = circle(3, 'mm'), end_cap = circle(3, 'mm')) + * geom_node_text(aes(label = name)) + theme_graph() ``` --- 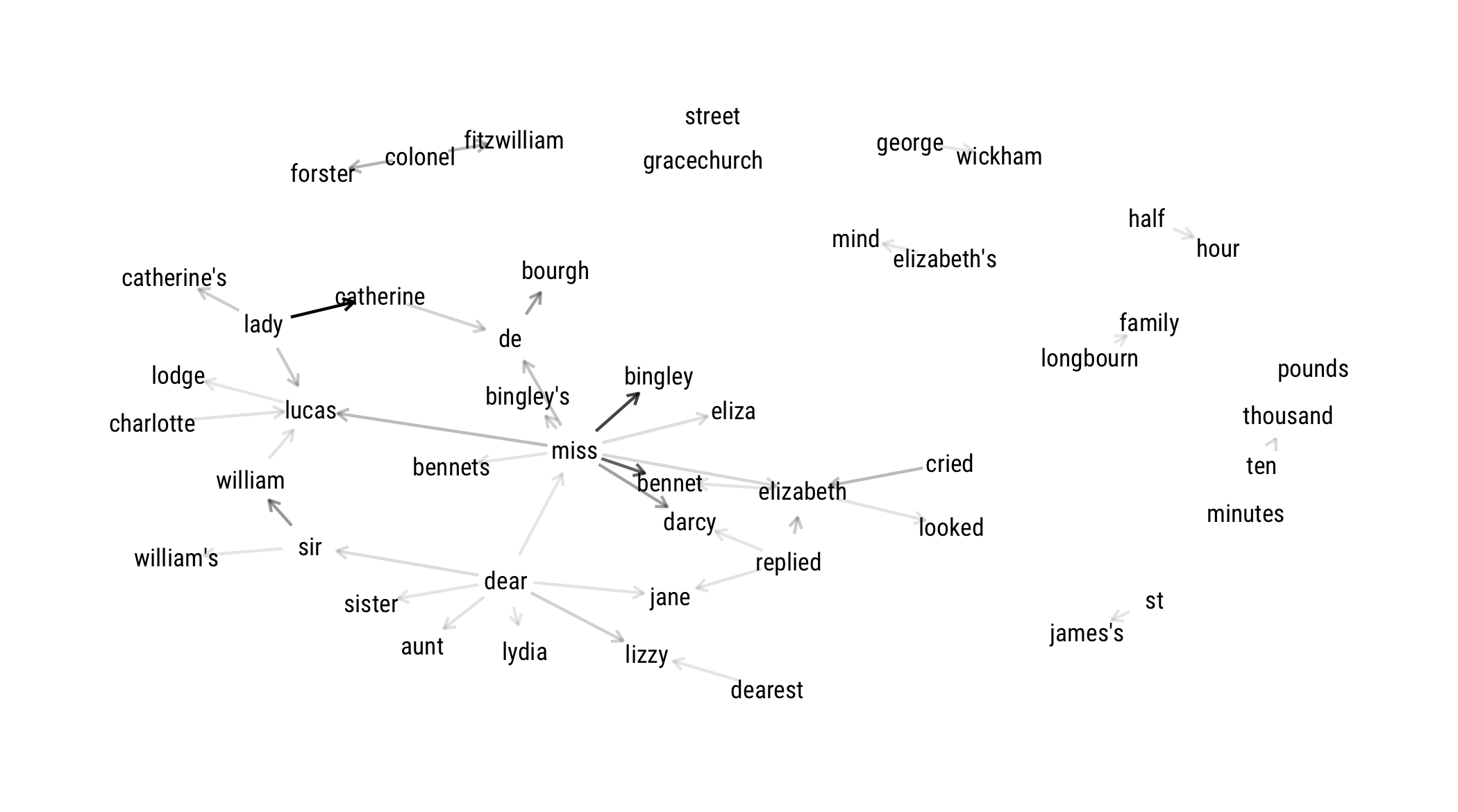<!-- --> --- class: left, middle <img src="figs/blue_jane.png" width="150px"/> # Thanks! <a href="http://twitter.com/juliasilge"><i class="fa fa-twitter fa-fw"></i> @juliasilge</a><br> <a href="http://github.com/juliasilge"><i class="fa fa-github fa-fw"></i> @juliasilge</a><br> <a href="https://juliasilge.com"><i class="fa fa-link fa-fw"></i> juliasilge.com</a><br> <a href="https://tidytextmining.com"><i class="fa fa-book fa-fw"></i> tidytextmining.com</a><br> <a href="mailto:julia.silge@gmail.com"><i class="fa fa-paper-plane fa-fw"></i> julia.silge@gmail.com</a> Slides created with [**remark.js**](http://remarkjs.com/) and the R package [**xaringan**](https://github.com/yihui/xaringan)